 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
OmniDiT: Extending Diffusion Transformer to Omni-VTON Framework
Mar 20, 2026Despite the rapid advancement of Virtual Try-On (VTON) and Try-Off (VTOFF) technologies, existing VTON methods face challenges with fine-grained detail preservation, generalization to complex scenes, complicated pipeline, and efficient inference. To tackle these problems, we propose OmniDiT, an omni Virtual Try-On framework based on the Diffusion Transformer, which combines try-on and try-off tasks into one unified model. Specifically, we first establish a self-evolving data curation pipeline to continuously produce data, and construct a large VTON dataset Omni-TryOn, which contains over 380k diverse and high-quality garment-model-tryon image pairs and detailed text prompts. Then, we employ the token concatenation and design an adaptive position encoding to effectively incorporate multiple reference conditions. To relieve the bottleneck of long sequence computation, we are the first to introduce Shifted Window Attention into the diffusion model, thus achieving a linear complexity. To remedy the performance degradation caused by local window attention, we utilize multiple timestep prediction and an alignment loss to improve generation fidelity. Experiments reveal that, under various complex scenes, our method achieves the best performance in both the model-free VTON and VTOFF tasks and a performance comparable to current SOTA methods in the model-based VTON task.
Awakening Dormant Users: Generative Recommendation with Counterfactual Functional Role Reasoning
Feb 13, 2026Awakening dormant users, who remain engaged but exhibit low conversion, is a pivotal driver for incremental GMV growth in large-scale e-commerce platforms. However, existing approaches often yield suboptimal results since they typically rely on single-step estimation of an item's intrinsic value (e.g., immediate click probability). This mechanism overlooks the instrumental effect of items, where specific interactions act as triggers to shape latent intent and drive subsequent decisions along a conversion trajectory. To bridge this gap, we propose RoleGen, a novel framework that synergizes a Conversion Trajectory Reasoner with a Generative Behavioral Backbone. Specifically, the LLM-based Reasoner explicitly models the context-dependent Functional Role of items to reconstruct intent evolution. It further employs counterfactual inference to simulate diverse conversion paths, effectively mitigating interest collapse. These reasoned candidate items are integrated into the generative backbone, which is optimized via a collaborative "Reasoning-Execution-Feedback-Reflection" closed-loop strategy to ensure grounded execution. Extensive offline experiments and online A/B testing on the Kuaishou e-commerce platform demonstrate that RoleGen achieves a 6.2% gain in Recall@1 and a 7.3% increase in online order volume, confirming its effectiveness in activating the dormant user base.
Multi-level Domain Adaptation for Lane Detection
Jun 21, 2022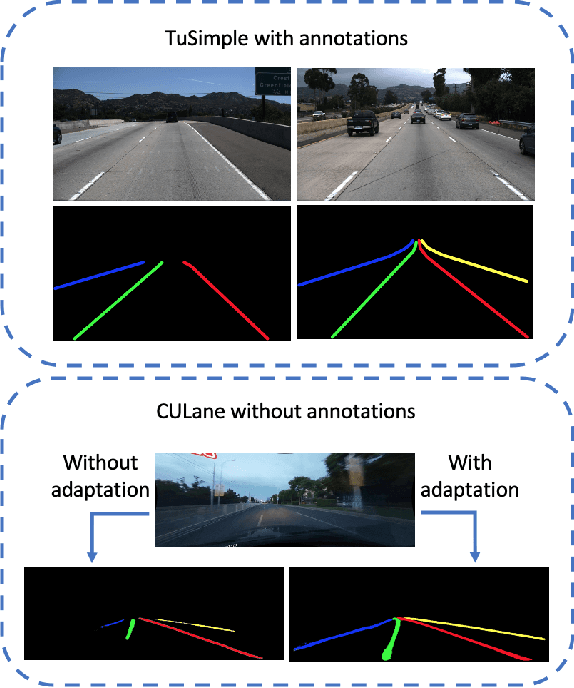

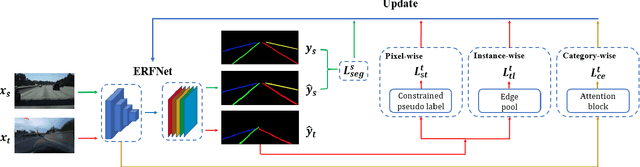
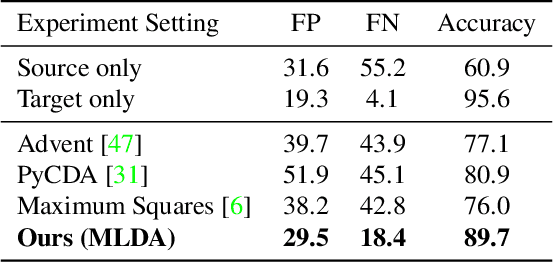
We focus on bridging domain discrepancy in lane detection among different scenarios to greatly reduce extra annotation and re-training costs for autonomous driving. Critical factors hinder the performance improvement of cross-domain lane detection that conventional methods only focus on pixel-wise loss while ignoring shape and position priors of lanes. To address the issue, we propose the Multi-level Domain Adaptation (MLDA) framework, a new perspective to handle cross-domain lane detection at three complementary semantic levels of pixel, instance and category. Specifically, at pixel level, we propose to apply cross-class confidence constraints in self-training to tackle the imbalanced confidence distribution of lane and background. At instance level, we go beyond pixels to treat segmented lanes as instances and facilitate discriminative features in target domain with triplet learning, which effectively rebuilds the semantic context of lanes and contributes to alleviating the feature confusion. At category level, we propose an adaptive inter-domain embedding module to utilize the position prior of lanes during adaptation. In two challenging datasets, ie TuSimple and CULane, our approach improves lane detection performance by a large margin with gains of 8.8% on accuracy and 7.4% on F1-score respectively, compared with state-of-the-art domain adaptation algorithms.
Multi-scale Neural Networks for Retinal Blood Vessels Segmentation
Apr 11, 2018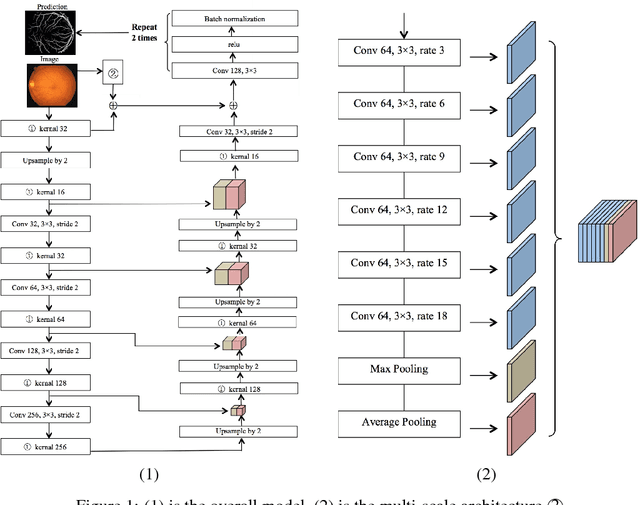
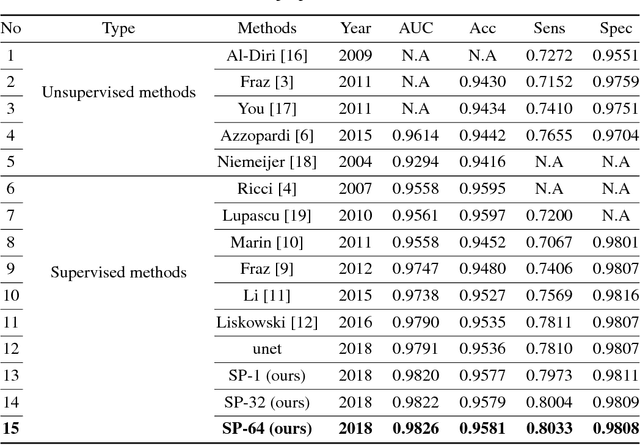

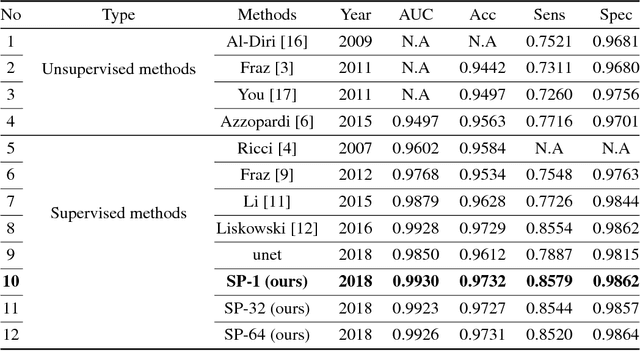
Existing supervised approaches didn't make use of the low-level features which are actually effective to this task. And another deficiency is that they didn't consider the relation between pixels, which means effective features are not extracted. In this paper, we proposed a novel convolutional neural network which make sufficient use of low-level features together with high-level features and involves atrous convolution to get multi-scale features which should be considered as effective features. Our model is tested on three standard benchmarks - DRIVE, STARE, and CHASE databases. The results presents that our model significantly outperforms existing approaches in terms of accuracy, sensitivity, specificity, the area under the ROC curve and the highest prediction speed. Our work provides evidence of the power of wide and deep neural networks in retinal blood vessels segmentation task which could be applied on other medical images tasks.